
MoE架构
DeepSeek 新模型 R1-0528 悄悄开源,与o3 相当,实测来了。
DeepSeek 团队发布新版本 DeepSeek R1-0528,性能提升,支持长时间推理和复杂问题解决。模型基于 DeepSeek-V3-0324 模型,架构不变但进行了改进的训练方法和更透明的推理机制。

字节新推理模型逆袭DeepSeek,200B参数战胜671B,豆包史诗级加强?
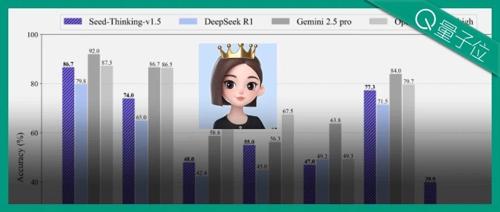
字节最新研发的Seed-Thinking-v1.5模型在数学、代码推理任务中表现优异,参数规模较小。该模型通过创新的数据处理方法、强化学习算法及基础设施优化提升了性能,并与其他领先模型进行了对比分析。
大,就聪明吗?论模型的“尺寸虚胖”
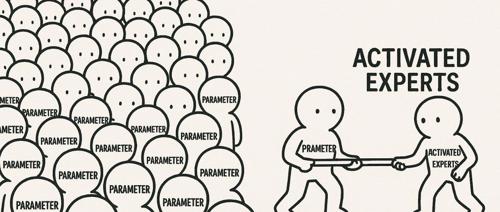
文章介绍了Gemma-3和DeepSeek V3在参数量上的对比,并指出模型效果不仅仅取决于参数大小。通过详细解释Dense和MoE架构的区别及其实际应用效果,强调了参数数量并不能直接反映模型性能优劣的观点。同时讨论了知识蒸馏技术如何让小模型继承大模型的能力,而不仅仅是关注模型的规模大小。

汤姆猫:AI产品已接入豆包、DeepSeek等模型能力,将开启海外市场的AI硬件布局

汤姆猫披露接待调研公告,公司AI机器人产品销售情况良好,并计划推进线上线下营销推广。团队详细介绍了机器人产品的售价、升级计划及竞争优势等内容。
支持“秒回”!腾讯推出混元新一代快思考模型 Turbo S了

腾讯发布混元 Turbo S模型,实现首字时延降低44%和吐字速度翻倍,重新定义人机交互即时性标准,揭示中国AI技术路径从’堆参数’到’拼效率’的转向。
