
AI正在改变高考!首个高考志愿大模型上岗,10分钟生成志愿报告

夸克宣布全面升级免费高考志愿填报服务,推出高考深度搜索、志愿报告和智能选志愿三大核心功能。今年算力投入扩大百倍,实现了从复杂问题询问到志愿报告输出的整个辅助决策流程。
夸克宣布全面升级免费高考志愿填报服务,推出高考深度搜索、志愿报告和智能选志愿三大核心功能。今年算力投入扩大百倍,实现了从复杂问题询问到志愿报告输出的整个辅助决策流程。

VidText 提出了一套全面的视频文本理解基准,覆盖 27 个真实场景和多种语言。它包含从视觉感知到跨模态推理的多个任务,评估模型在不同粒度上的表现,并揭示了影响性能的关键因素。

大语言模型驱动的多智能体系统在构建时面临手动设计和调试的瓶颈。新加坡国立大学等团队推出MaAS框架,利用智能体超网技术实现按需定制的动态智能体服务,提高效率并降低成本。

今天是2025年6月12日,星期四,北京晴。文章介绍了两种PPT生成方案AutoPresent和SlideCoder,前者通过微调LLAMA模型生成Python代码,后者使用布局感知的检索增强生成框架,包含层次化检索增强生成、图像分割等技术。
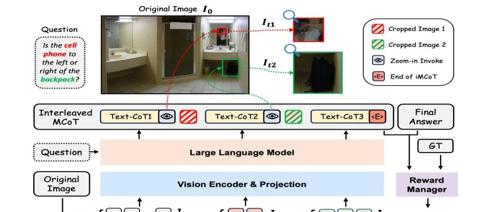
DeepEyes项目通过强化学习实现’用图思考’能力,在视觉搜索、幻觉缓解和多模态推理等方面表现出色,有望应用于教育、医疗、交通等领域。




