怎么学习设计和训练一个大模型——也就是神经网络?
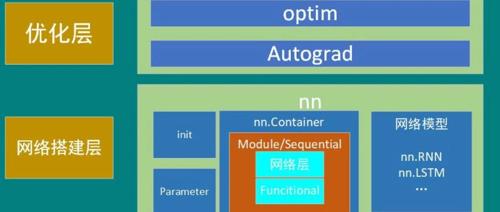
设计大模型需要先从技术点切入。建议初学者选择合适的工具(如PyTorch框架)和理论(如Transformer架构),专注于学习一种技术方向,并逐步理解其核心思想。
设计大模型需要先从技术点切入。建议初学者选择合适的工具(如PyTorch框架)和理论(如Transformer架构),专注于学习一种技术方向,并逐步理解其核心思想。

Mesorch 模型首次提出从介观表征的角度融合非语义信息和语义信息,构建并行多尺度 CNN 与 Transformer 网络混合架构来提高图像篡改检测性能。
在文章中提到,通过PyTorch框架可以实现神经网络模型,并且PyTorch作为科学计算框架,主要用于进行数学运算。同时,文章也强调了Transformer架构的重要性及其与PyTorch的关系。总的来说,它说明了如何借助工具(如PyTorch)来构建和运行神经网络,并依靠理论(如Transformer)来指导其有效运作。
Lucas Beyer分析了微软提出的DiffTransformer论文,指出其通过两个注意力头的差值来改善Transformer模型信噪比的问题。尽管存在一些质疑,Beyer认为该方法具有简单而有效的创新点,并强调需要更多图表和实验结果以验证其潜力。
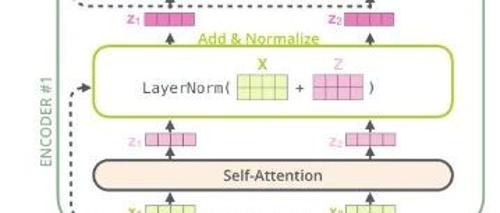
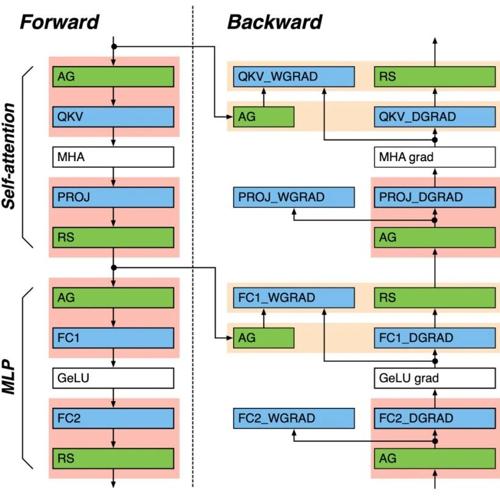
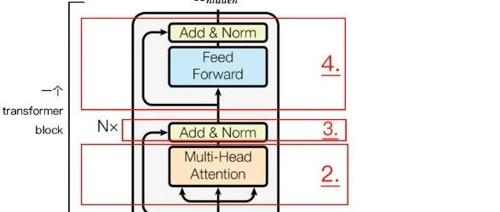
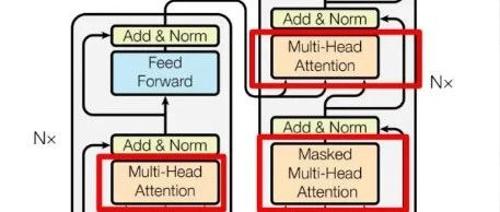
Transformer的编码器负责将人类可识别的数据转换为大模型可以处理的形式,并进行特征提取;解码器则用于重建模式,生成新的数据。其架构包括自注意力机制等多重数据处理步骤。