仅128个token达到ImageNet生成SOTA性能!MAETok:有效的扩散模型的关键是什么?
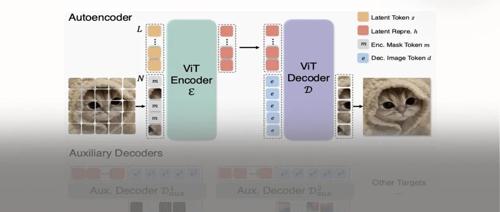
ETok在仅使用128个token的情况下,于256×256和512×512分辨率的ImageNet
ETok在仅使用128个token的情况下,于256×256和512×512分辨率的ImageNet

来自港中文、北大和上海AI Lab的研究团队将思维链(CoT)与生成模型结合,显著提高了自回归图像生成的质量,并提出了潜力评估奖励模型(PARM)及其增强版本(PARM++),进一步优化了图像生成质量。

《Understanding Deep Learning》是一本关于深度学习的专业书籍,涵盖理论基础、性能评估等多个主题,并附有大量练习题。

上海交通大学提出SiTo方法,通过基于相似性的令牌剪枝技术,无需训练且硬件友好地加速扩散模型。显著提升了生成质量并减少了内存和计算成本。

这是一款开源的零样本人像视频动画项目X-Dyna,它能够通过驱动面部表情和身体动作将单张人像图片动画化,并且还能让背景动起来。该技术由扩散模型、动态适配器模块、局部控制模块等组成,能够生成流畅的肢体动作和自然的环境效果。
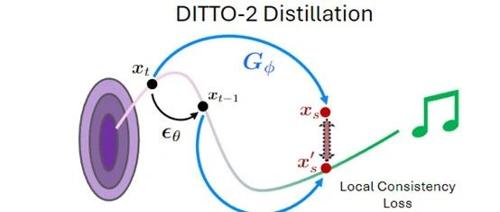
全球多媒体巨头Adobe联合加州大学发布创新音乐模型DITTO-2,大幅提升生成效率和控制能力。通过模型蒸馏和推理时间优化技术实现高效精准音乐生成。

英伟达发布Cosmos模型,基于200万小时视频训练,包含扩散模型、自回归模型等四大功能模块。Cosmos在几何准确性上表现优异,适用于自动驾驶和机器人研究等场景。