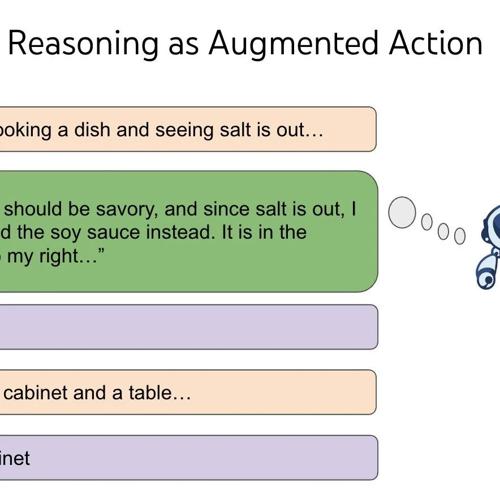
新SoTA方法RM-R1:让reward model对评分说出原因!超越GPT4o

MLNLP社区致力于促进国内外机器学习与自然语言处理的交流合作。近期发表论文提出推理奖励模型ReasRM,通过两阶段训练让小模型学会写评语,并在综合、数学题等测试集中优于GPT-4。该模型支持任务分类和动态奖励机制,已在多个领域展示优势。
MLNLP社区致力于促进国内外机器学习与自然语言处理的交流合作。近期发表论文提出推理奖励模型ReasRM,通过两阶段训练让小模型学会写评语,并在综合、数学题等测试集中优于GPT-4。该模型支持任务分类和动态奖励机制,已在多个领域展示优势。

BrowseComp-ZH团队发布新基准测试集,对20多个主流大模型进行中文网页能力测试,结果显示多数模型在中文互联网检索上准确率低于10%,仅有少数能突破20%。研究揭示了模型在中文信息环境中的“死角”,强调了推理能力和多轮策略的重要性,并指出搜索功能的不当使用可能误导模型。

文章讲述了明星自拍合照、影视剧人物打卡合影以及AI生成照片的热潮,并指出随着AI技术的进步,辨识真假变得愈发困难。提醒读者提高媒介素养和平台监管的重要性。
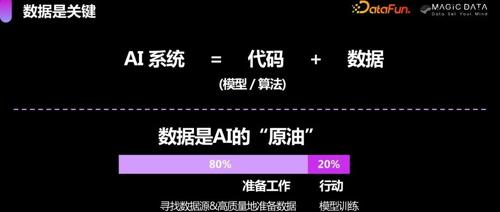
阿里开源的Qwen2.5系列训练数据规模达18万亿 token,推动AI大模型发展。但大规模训练带来幻象问题,RAG技术及工业场景应用以数据为中心成为趋势。国家和行业正积极推进数据标注产业发展规范,提升数据标注行业的合规能力。

GPT-4和DreamTech的最新多模态大模型Neural4D 2o在3D生成领域取得突破,支持文本、图像及3D输入,实现上下文一致性、高精准局部编辑等功能。Neural4D 2o降低了3D内容创作门槛,有望让3D设计师成为历史。
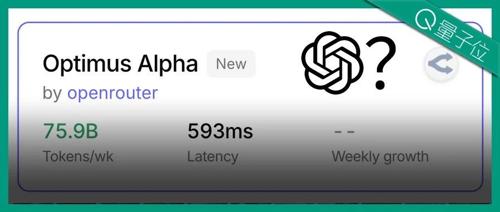
上线仅三天的Optimus Alpha模型已处理772亿Token,性能优异。它在编程、创意写作等方面表现突出,并被怀疑来自OpenAI。

OpenAI宣布,即将在4月30日下线GPT-4,由更强的GPT-4o全面替代。目前,OpenAI还准备了一大批新模型包括GPT-4.1、GPT-4.1 mini/nano和下一代推理模型o系列等。这些新模型正在筹备中,以应对GPT-4退役后的需求。
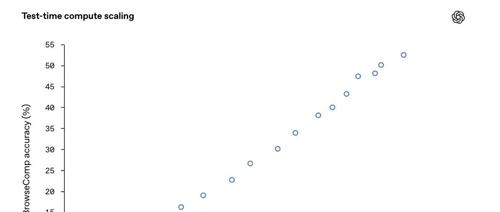
OpenAI 发布并开源 BrowseComp 基准测试,旨在评估智能体在互联网上精准定位极难查找信息的能力,以应对现有评估方法的不足。

2025年斯坦福《AI指数报告》揭示全球AI现状:技术加速进化、政府加码布局、顶尖人才涌向大模型公司,创新集中于少数巨头。尽管存在伦理风险和技术瓶颈,但AI正快速融入各行各业并改变人们的生活方式。