Artificial Analysis:DeepSeek成为世界前二AGI实验室

DeepSeek R1-0528版本超越xAI、Meta等成为全球第二大人工智能实验室,并与谷歌并列。其智能指数得分从60分跃升至68分,超过多个顶级模型,提升主要体现在数学竞赛、代码生成和推理方面。
DeepSeek R1-0528版本超越xAI、Meta等成为全球第二大人工智能实验室,并与谷歌并列。其智能指数得分从60分跃升至68分,超过多个顶级模型,提升主要体现在数学竞赛、代码生成和推理方面。
UC Berkeley团队提出的新方法Intuitor通过优化模型自身的置信程度来提升大模型的复杂推理能力,无需外部奖励信号或标准答案。与传统强化学习相比,Intuitor能有效减少无效响应并提高模型在数学和代码生成任务中的表现。

本文提出ZeroSearch框架,无需真实搜索引擎即可激活大语言模型搜索能力。通过轻量级监督微调将LM转为检索模块,并采用课程学习逐步降低文档质量来激发推理能力,显著降低训练成本和提高性能。
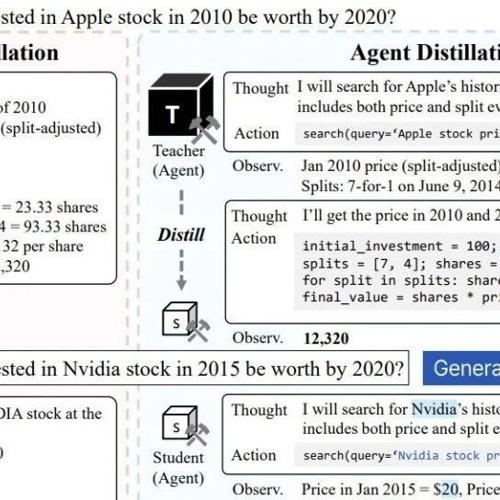
MLNLP社区是国内外知名的机器学习与自然语言处理社区。该社区致力于促进学术界、产业界和爱好者间的交流与进步,特别是针对初学者的提升。近期有论文提出Agent蒸馏技术,通过使用检索工具和代码工具让小模型学会像人类一样解决问题,显著提升了小模型在某些任务上的性能。

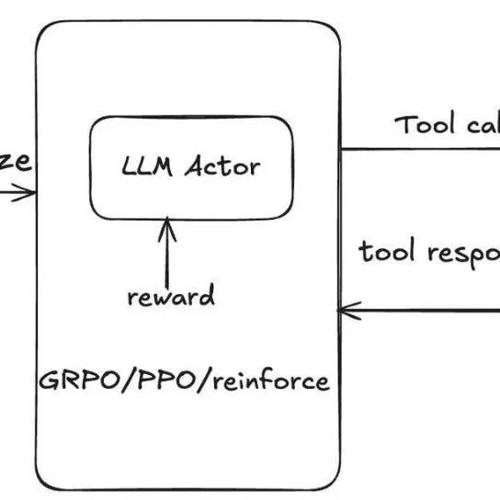
2025年5月28日,北京晴。文章探讨了从几张图看RAG及Agent的问题和基于自我置信度作为强化学习监督信号的工作,强调实际业务数据的重要性,并指出不要过度依赖Agent智能体解决问题。
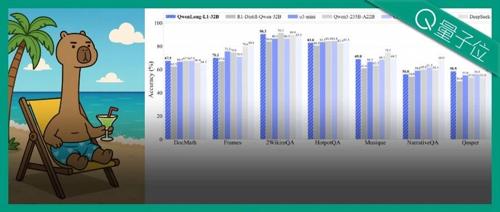
阿里开源的QwenLong-L1模型在HuggingFace今日热门论文第二,其32B参数版本性能优秀。对比基础模型,QwenLong-L1通过回溯和验证机制成功处理了长文本推理中的干扰信息问题,准确计算了金融文档中涉及优先票据发行成本与第一年利息支出合并的总资本成本。