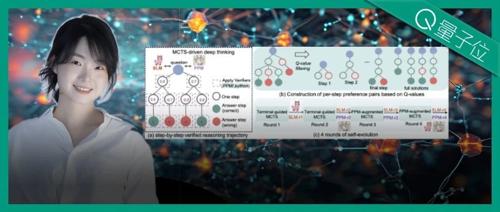
中兴星云拿下推理总分榜一!SuperCLUE 5月成绩出炉

中兴通讯星云大模型在推理榜单上荣获总分第一,并在数学、科学及代码生成等细分领域表现突出。它还通过了国家级权威安全认证,成为业内少数拥有双安全认证的大模型产品。
中兴通讯星云大模型在推理榜单上荣获总分第一,并在数学、科学及代码生成等细分领域表现突出。它还通过了国家级权威安全认证,成为业内少数拥有双安全认证的大模型产品。
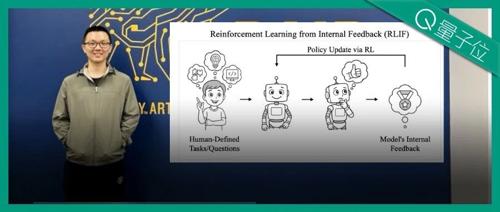
UC Berkeley团队提出的新方法Intuitor通过优化模型自身的置信程度来提升大模型的复杂推理能力,无需外部奖励信号或标准答案。与传统强化学习相比,Intuitor能有效减少无效响应并提高模型在数学和代码生成任务中的表现。
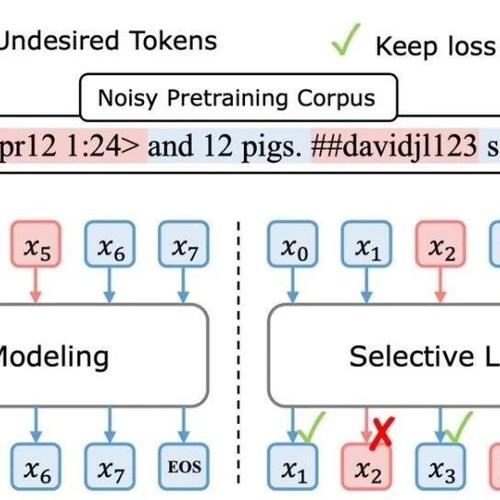
MLNLP社区分享了关于RHO-1论文的解读,该论文提出了选择性语言建模(SLM),通过分析文本中的不同token对模型学习的影响,提出只对有价值的token进行训练的方法。此方法能够显著提升效率并提高性能。

最近研究发现仅使用一个数学训练数据就能大幅提升大型语言模型在数学推理任务上的表现,论文提出了1-shot RLVR方法,并展示了其在多个数学和非数学推理任务上的应用效果。
清华大学和上海人工智能实验室提出测试时强化学习(TTRL),通过在无标签数据上利用多数投票等方法估计奖励信号来提升大规模语言模型性能。

本文提出Entropy Minimized Policy Optimization (EMPO)方法,旨在实现完全无监督条件下大模型推理能力的提升。该方法不需要监督微调或人工标注的答案,仅通过强化学习训练从基模型中获得策略,并利用语义相似性聚类生成的多个回答作为奖励信号,从而在数学及其他通用推理任务上取得显著性能提升。