
深度学习

AI之父Hinton:想知道不是最聪明物种的感觉?去问鸡吧

AI教父Geoffrey Hinton警告人类可能被创造的数字生命取代,他认为这将是坏事。他用鸡的例子比喻人类将变得无关紧要。这一言论引发广泛讨论,有人认为Hinton疯了,但更多人开始认真思考。
低调升级,实力暴涨!新版 DeepSeek R1,成了 o3 和 Gemini 2.5 的最强平替
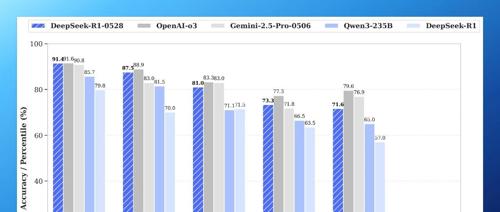
DeepSeek R1 推出升级版,推理能力增强、幻觉率下降、支持函数调用,并引入8B小模型辅助教学。新版性能提升显著,已超越开源之王Qwen3。
DeepSeek节前又双叒叕搞事,R1“小版本试更新”代码能力实测堪比Claude 4

DeepSeek官方近日宣布已完成DeepSeek R1模型的小版本试升级,并在HuggingFace上开源了新版本。该模型在代码生成方面提升显著,性能接近OpenAI的模型且超越Claude-4-Sonnet,但推理能力稍有不足。

UC Berkeley最新VideoMimic的框架:基于视觉模仿学习的类人机器人跨环境控制策略生成方法
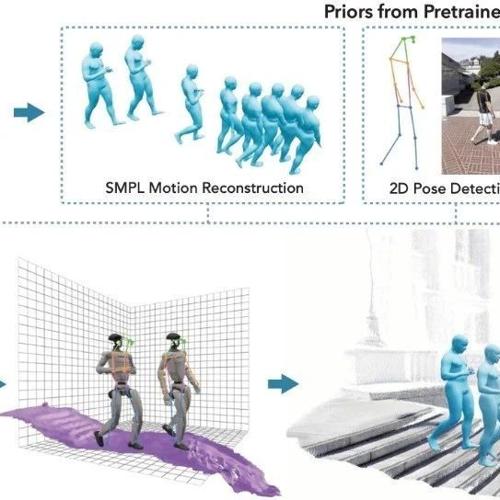
近日UC Berkeley大学研究人员提出VideoMimic框架,通过观看普通视频自动生成类人机器人的控制策略。无需复杂传感器数据或手工奖励函数,机器人能在多种环境下执行任务。

四位图灵奖掌舵,2025智源大会揭示AI进化新路径

第七届北京智源大会将于2025年6月6日至7日在中关村国家自主创新示范区展示中心举行,汇聚全球顶尖研究者分享最新成果。大会将围绕人工智能四大主题展开,包括基础理论、应用探索、产业创新和可持续发展等,设有近20场专题论坛。