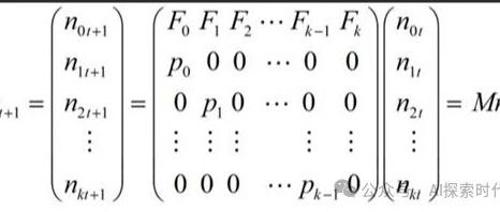
Transformer架构

刚刚!大模型的门槛,又被打下来了!

DeepSeek爆火,高性能低成本让企业接入AI成为必然趋势。年薪高达154W的大模型全栈工程师等岗位火热招聘,普通程序员面临被AI替换风险。知乎知学堂推出大模型应用开发工程师速成计划,免费学习名额仅限100人,助力入局大模型开发及提升竞争力。
吊打ChatGPT,脚踩Claude:DeepSeek 自我介绍

大模型已成为中国AI研究主流。DeepSeek在中文语义处理方面表现出色,成功翻译了俄罗斯教授的经济学导论。DeepSeek还提供了文本生成、分类与情感分析、问答系统等多样的功能。


仅缩小视觉Token位置编码间隔,轻松让多模态大模型理解百万Token!清华大学,香港大学,上海AI Lab新突破

文章介绍了V2PE(Variable Vision Position Embedding),一种用于增强视觉-语言模型在长上下文场景表现的位置编码方法。通过实验验证了其有效性和优势,为视觉-语言模型的发展带来了新的机遇。
关于神经网络的输入格式——数据集的处理。关于神经网络模型的结构说明

开发大模型包括数据集处理、模型设计与训练等步骤,以Transformer为例详解其结构;主要包含输入嵌入、编码器解码器架构和多头注意力机制等内容。