
微软&清北RPT:强化学习的风又吹到了预训练!
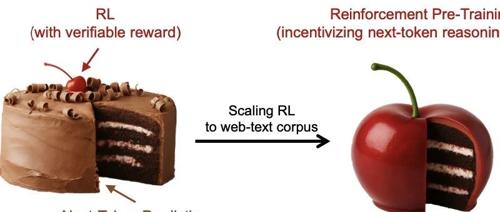
微软研究院、北大和清华联合提出强化预训练新范式RPT,通过RL训练提高LLMs预训练性能。该方法在OmniMATH数据集上优于现有模型,并且随着计算量增加预测准确性提升。
微软研究院、北大和清华联合提出强化预训练新范式RPT,通过RL训练提高LLMs预训练性能。该方法在OmniMATH数据集上优于现有模型,并且随着计算量增加预测准确性提升。

近日,微软研究院与北京大学联合发布的新框架Next-Frame Diffusion(NFD)实现了每秒超过30帧的视频生成速度,并保持高质量画面。相比现有自回归视频生成模型,NFD采用帧内双向注意力和帧间因果依赖机制建模视频,并通过多步迭代和并行采样提高效率。
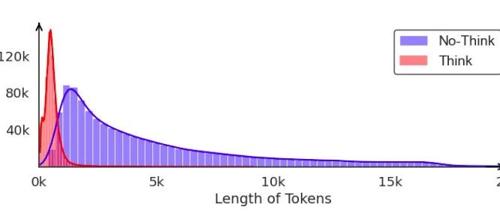
微软研究院与北大提出的大规模混合推理模型LHRMs能够在用户查询时自适应地决定是否进行思考,实现更快、更自然的日常交互,并在推理和通用能力方面超越现有模型的同时显著提高了效率。

Sonora是由微软研究院开发的人工智能系统,提供实时语音驱动的沉浸式3D音频环境创建与导航,旨在通过个性化和互动性促进放松并减轻焦虑。

微软研究院开源了实时交互世界模型MineWorld,以Transformer为核心结合《我的世界》。MineWorld参数量少于Oasis,在多方面表现更优,包括视频质量、可控性和推理速度等方面。MineWorld架构由Transformer解码器、视觉标记器和动作标记器组成,实现高效并行解码算法提高生成效率。
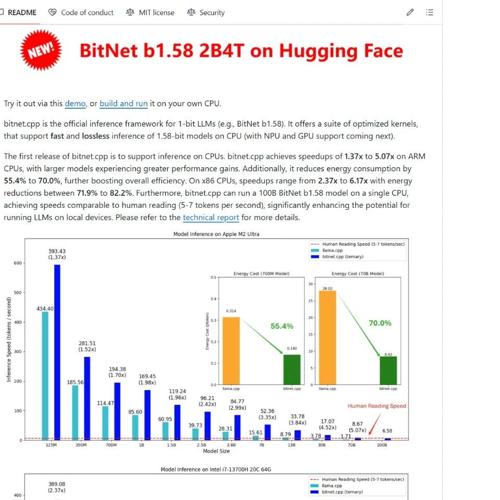
微软发布原生1-bit大语言模型bitnet-b1.58-2B-4T,其在内存占用和CPU推理延迟上大幅降低,并且性能接近全精度模型。

微软研究院开源Magma模型,首个能理解多模态输入并进行实际操作的基础模型,在CVPR会议上获得接收。该模型融合视觉、语言与动作能力,使用Set-of-Mark和Trace-of-Mark两大标注方法提高准确性。


