推理延展到真实物理世界,英伟达Cosmos-Reason1:8B具身推理表现超过OpenAI ο1
答案的情况,比如以下例子:
根据视频中本车的动作,它接下来最有可能立即采取的行动是什么?
A:右转,
答案的情况,比如以下例子:
根据视频中本车的动作,它接下来最有可能立即采取的行动是什么?
A:右转,

OpenAI发布了两款新的音频模型GPT-4o-transcribe和GPT-4o-mini-transcribe,旨在提升语音转文本的准确性,并引入可操控性文本转语音功能。此举为自然、直观的口语对话迈出了重要一步。
深入剖析R1-Zero训练方法,发现其已展现‘灵光一现’现象,并提出Dr. GRPO算法优化强化学习过程。仅用8×A100 GPU在27小时内实现SOTA性能。

新加坡国立大学与海航人工智能实验室团队提出了一篇关于R1-Zero-like训练的新论文。文章详细分析了基座模型和强化学习(RL)两大基石,并指出现有方法可能存在偏见问题,提出了改进方案。

今天是2025年3月23日,星期日。文章介绍了Fin-R1模型在金融领域的应用及其构建路线,包括数据处理和训练方法,并总结了减少推理大模型过度思考的技术方案。
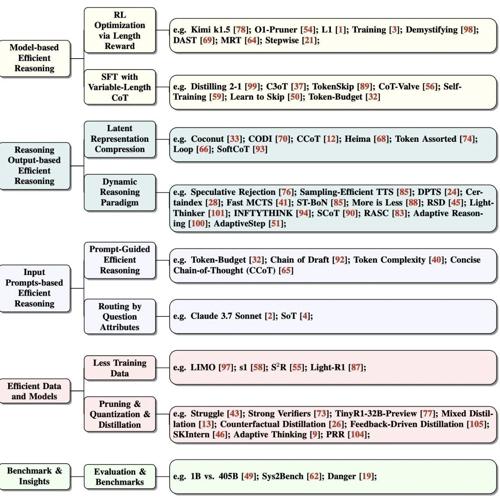
MLNLP社区是国内外知名的人工智能学术社区,其愿景是促进机器学习与自然语言处理领域内的交流合作。论文《Stop Overthinking》探讨了高效推理的方法及其在自动驾驶和医疗诊断等领域的应用挑战,提出模型优化、动态压缩和提示工程三大方向的研究进展及未来展望。

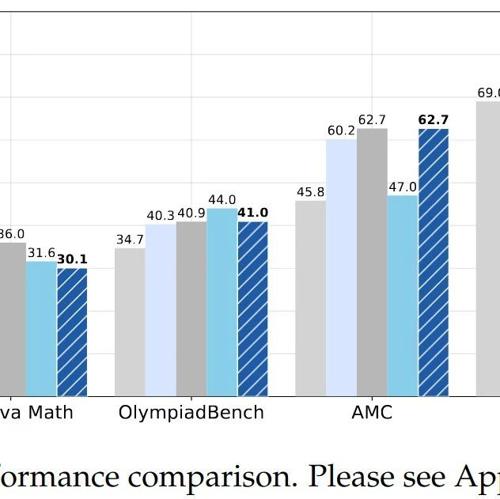
腾讯发布混元-T1深度思考模型,在长文捕捉、优化长序列处理及强化学习训练等方面取得突破,已在公开benchmark和内部人工体验集上表现出色。